Since 2007, geospatial extensions of SPARQL, like GeoSPARQL and stSPARQL, have been defined and corresponding geospatial RDF stores have been implemented. In addition, some work on developing benchmarks for evaluating geospatial RDF stores has been carried out. In this paper, we revisit the Geographica [2] benchmark defined by our group in 2013 which uses both real world and synthetic data to test the performance and functionality of geospatial RDF stores. We present Geographica 2, a new version of the benchmark which extends Geographica by adding one more workload, extending our existing workloads and evaluating 5 more RDF stores. Using three different real workloads, Geographica 2 tests the efficiency of primitive spatial functions in RDF stores and the performance of the RDF stores in real use case scenarios, a more detailed evaluation is performed using a synthetic workload and the scalability of the RDF stores is stressed with the scalability workload. In total eight systems are evaluated out of which six adequately support GeoSPARQL and two offer limited spatial support.
The machine that was used to run the benchmark is equipped with two Intel Xeon E5620 processors with 12MB L3 cache running at 2.4 GHz, 32 GB of RAM and a RAID-5 disk array that consists of four disks. Each disk has 32 MB of cache and its rotational speed is 7200 rpm. The operating system for all RDF stores was Ubuntu 12.04, except System X which had to be tested in its own Linux distribution since it does not officially support Ubuntu. Operating system tuning involved customizing /etc/sysctl.conf.
Strabon and uSeekM utilize PostgreSQL enhanced with PostGIS as a spatially-enabled relational back-end. For these systems, an instance of Postgres 9.5 with PostGIS 2.0 was used, which was tuned through postgresql.conf to make better use of the system resources.
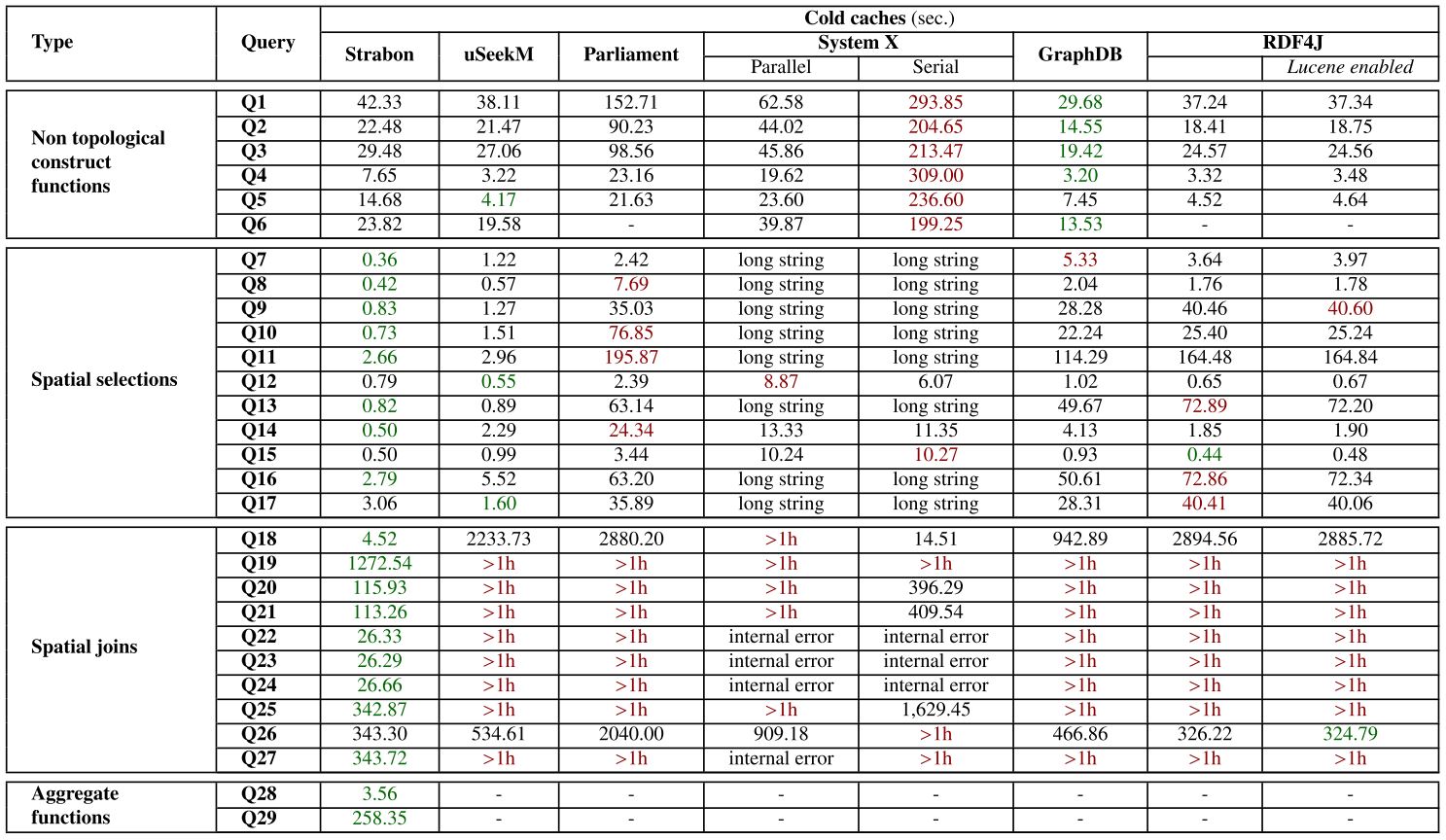
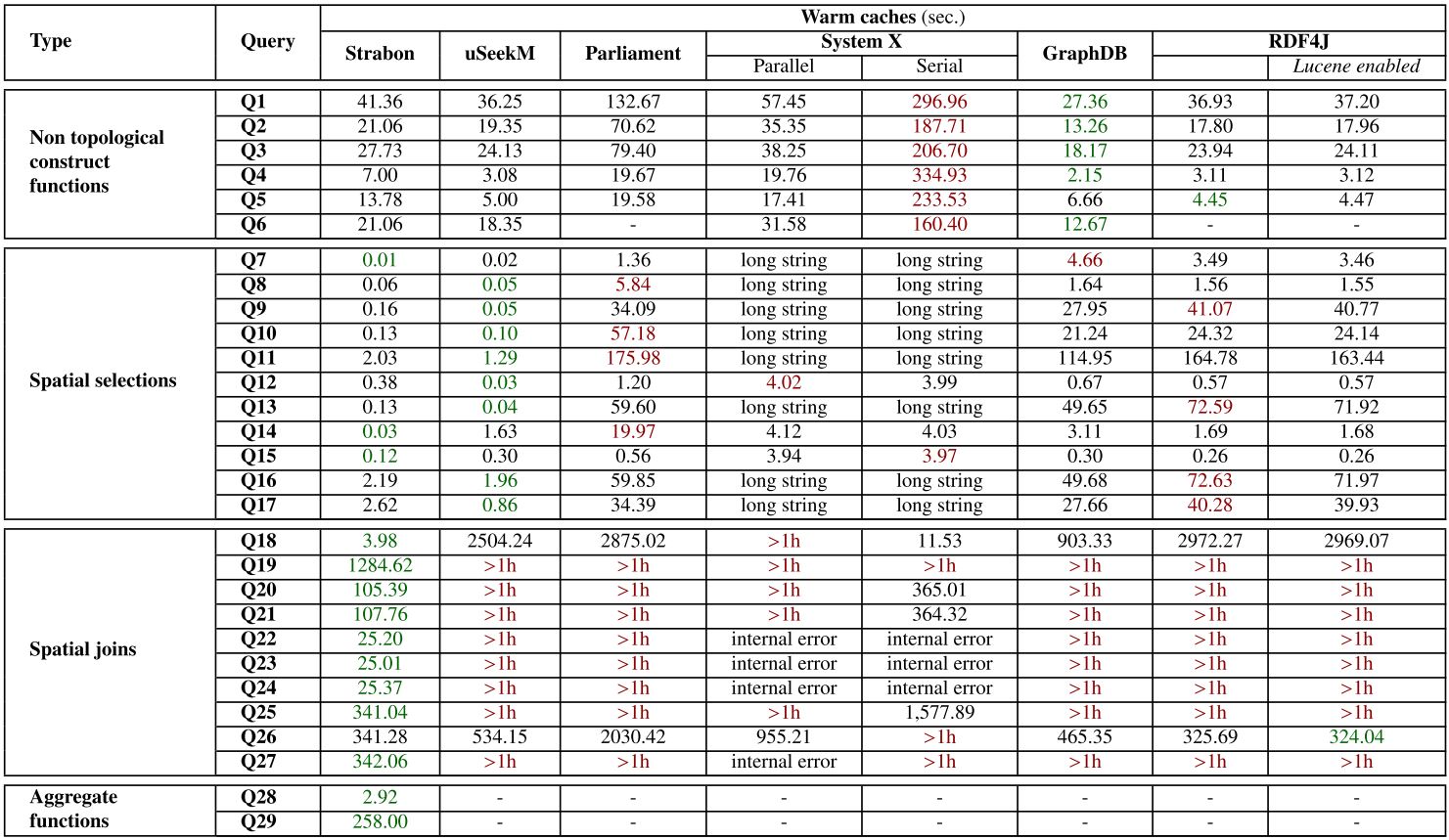
Each query in the micro benchmark of the real world workload and entirely for the synthetic and scalability workloads was run three times on cold and warm caches. For warm caches, each query ran once before measuring the response time, in order to warm up the caches. We measured the response time of each query by measuring the elapsed time from submitting the query until a complete iteration over the results had been completed. The response time of each query was measured and the median of each measurement is reported. For the macro benchmark of the real world workload, each scenario ran many times for one hour without cleaning the caches for this period and the average time for a complete execution of all queries of each scenario are reported. The time limit for each query of the real world and synthetic workloads was set to one hour, while for the scalability workload the time limit was twenty four hours.
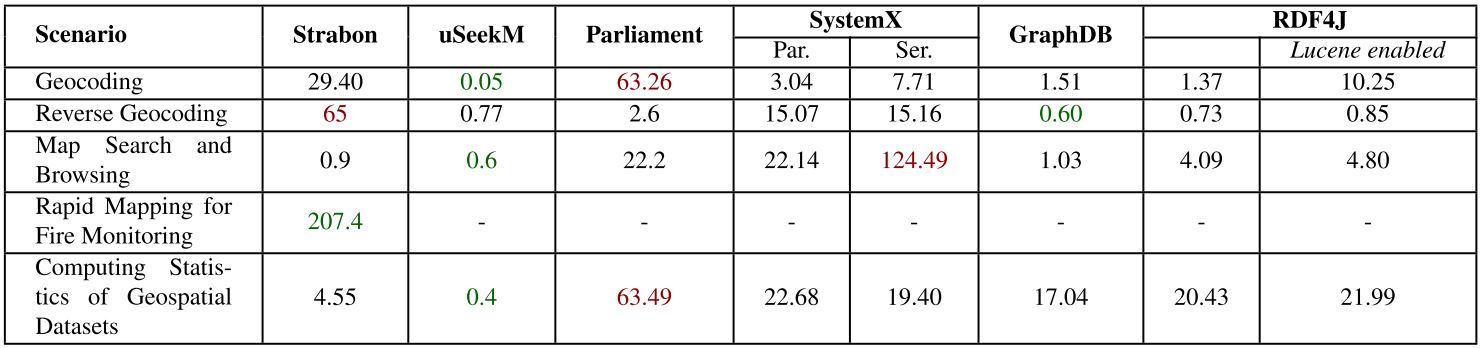
The real-world workload uses publicly available linked geospatial data. This workload consists of a micro benchmark and a macro benchmark. The micro benchmark tests primitive spatial functions. We check the spatial component of a system with queries that use non-topological functions, spatial selections, spatial joins and spatial aggregate functions. In the macro benchmark we test the performance of the selected RDF stores in typical application scenarios like geocoding, reverse geocoding, map search and browsing, a real-world use case from the Earth Observation domain and finally, we compute aggregations over simple spatial selections or spatial joins of the geospatial datasets.
In the second workload of Geographica we use a generator that produces synthetic data of various sizes and generates queries of varying thematic and spatial selectivity. In this way, we can perform the evaluation of geospatial RDF stores in a controlled environment.
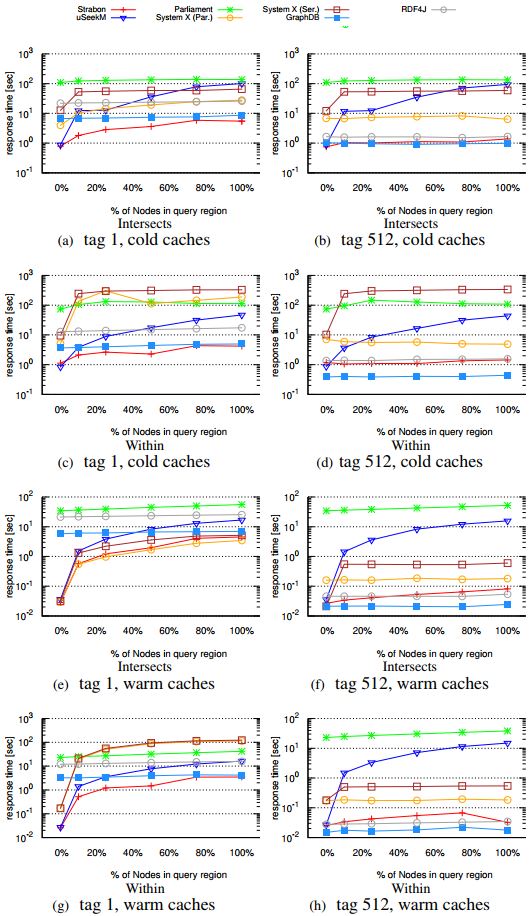
The scalability workload aims at discovering the limits of the systems under test as the number of triples in the dataset increase. Each system is tested against six increasingly bigger, proper subsets of the reference dataset which has approximately 500M triples. The scalability datasets used are: 10K, 100K, 1M, 10M, 100M and 500M triples.
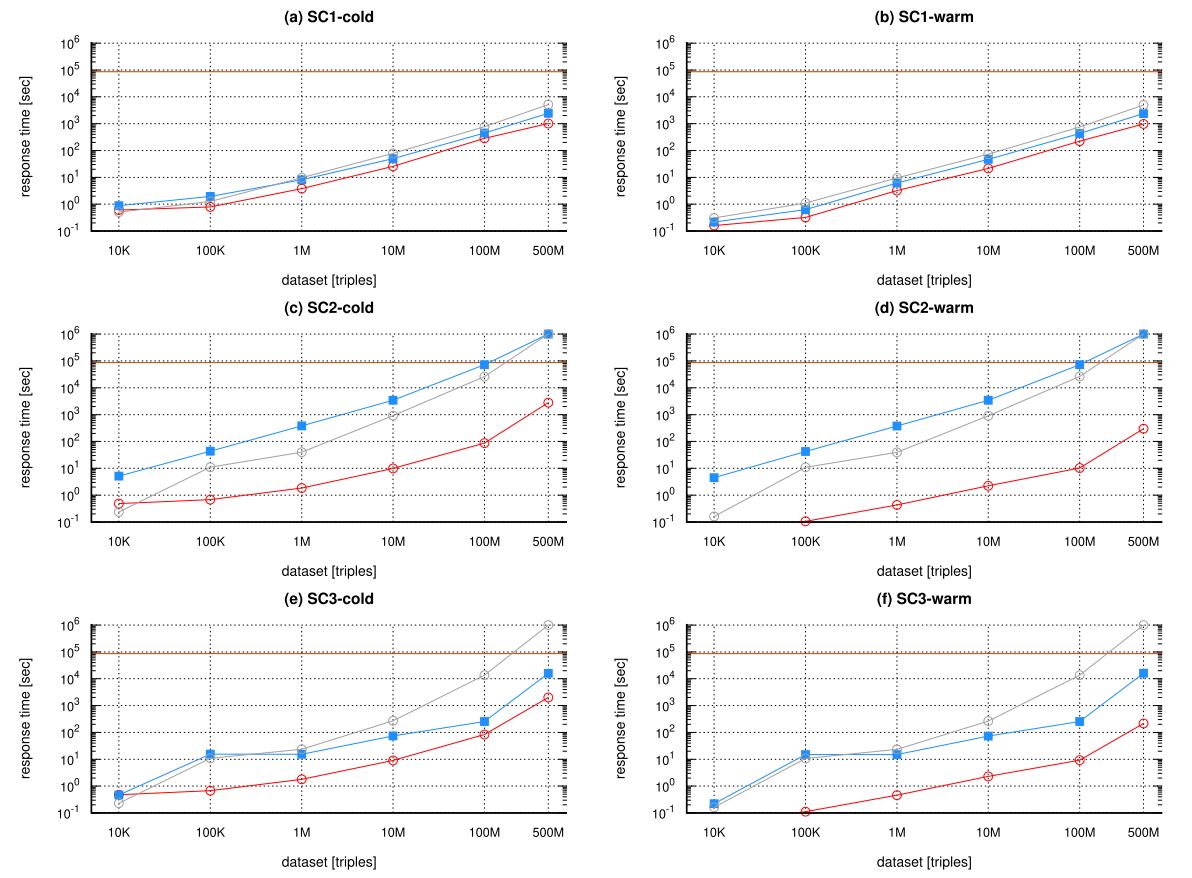
We have performed experiments using Geographica2 for the following geospatial RDF stores:
Geographica2 is an open source Java project that utilizes Apache Maven as a build automation tool.
A user can get a clone of the Geographica2 Mercurial repository which contains all systems tested by executing the following command:
$ hg clone http://hg.strabon.di.uoa.gr/Geographica2
A user can get a clone of the Geographica2 Git repository which contains all systems tested by executing the following command:
$ git clone https://github.com/AI-team-UoA/Geographica2